Présentation du model de reranking
Reranking Model
Le reranking est une technique utilisée dans les systèmes de recherche ou les pipelines RAG (Retrieval-Augmented Generation) pour améliorer la pertinence des résultats.
Exemple,dans un système RAG, une requête utilisateur doit être comparée à un grand nombre de documents afin de retrouver les informations les plus pertinentes. Selon les cas, ces bases de connaissances peuvent contenir des milliers, des millions, voire des milliards de documents. Il est donc essentiel de disposer d’un mécanisme de recherche rapide et efficace.
Pour répondre à ce besoin, les systèmes RAG utilisent généralement la recherche vectorielle.
Recherche vectorielle et embeddings
La recherche vectorielle consiste à transformer les contenus textuels en vecteurs numériques appelés embeddings.
Ces vecteurs représentent le sens du texte dans un espace vectoriel multidimensionnel. Dans cet espace, les textes ayant une signification proche se retrouvent également proches les uns des autres.
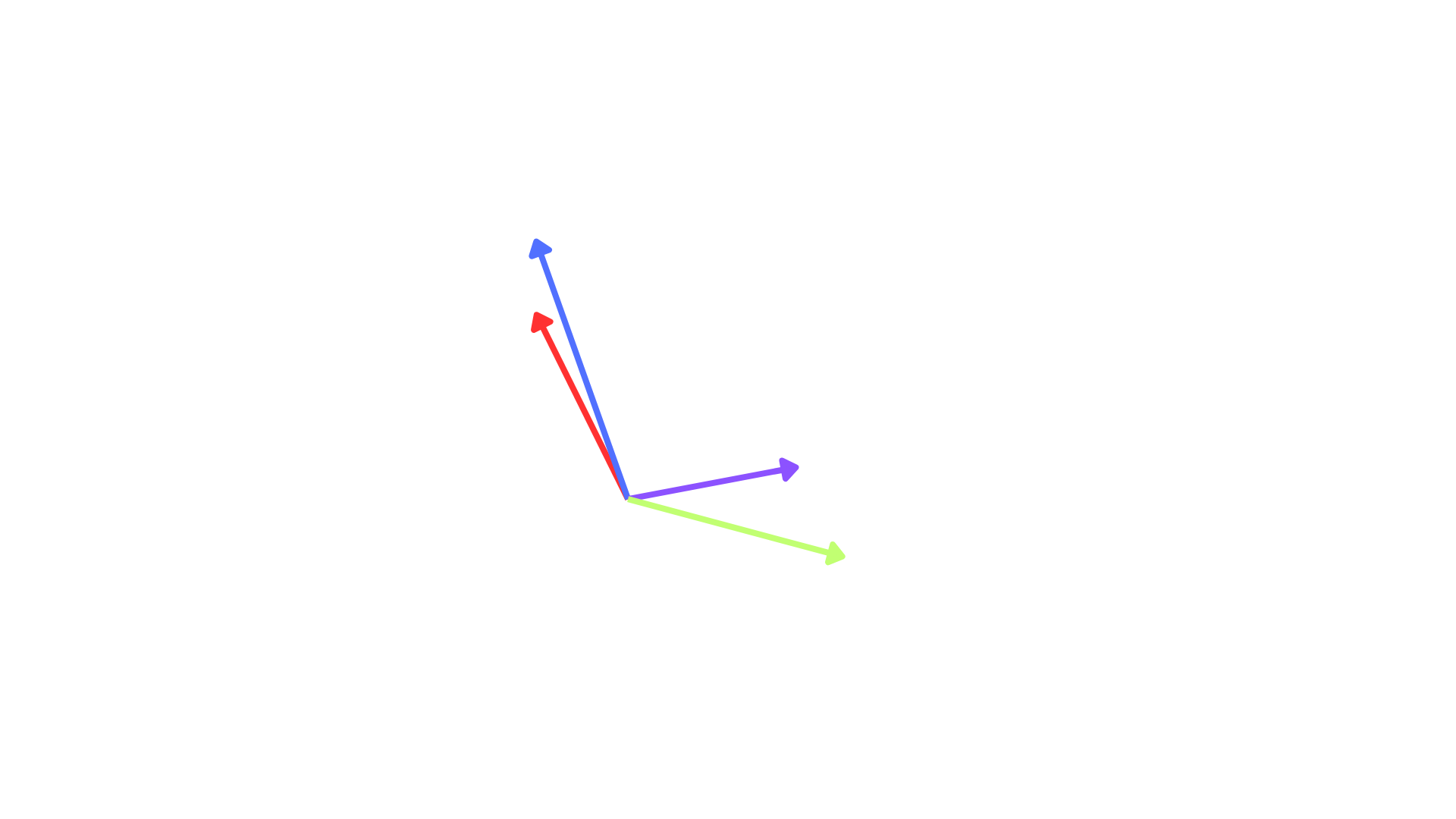
Dans cet exemple simplifié, chaque mot est représenté par un vecteur. On observe que certains mots se situent dans des directions similaires :
- Clovis et Roi sont proches
- Escalade et Montagne sont proches
- certaines relations sémantiques apparaissent comme des transformations vectorielles
Cette représentation permet aux systèmes de recherche de comparer le sens des textes, plutôt que simplement leurs mots.
Une fois les documents convertis en vecteurs, ils sont stockés dans une base vectorielle. Lorsqu'une requête est effectuée, celle-ci est également transformée en vecteur. Le système compare ensuite ce vecteur avec ceux de la base pour identifier les documents les plus proches.
Limites de la recherche vectorielle
Même si cette approche est très efficace pour effectuer des recherches à grande échelle, elle présente une limite importante.
Les embeddings sont une représentation condensée du contenu d’un texte. Cela signifie qu’une partie de l’information originale est perdue lors de la projection dans l’espace vectoriel.
Conséquence :
les documents récupérés en tête des résultats ne sont pas toujours les plus pertinents pour répondre précisément à la question de l’utilisateur.
Certains documents importants peuvent ainsi apparaître plus bas dans le classement, simplement parce que leur représentation vectorielle est moins proche du vecteur de la requête.
Limites liées aux LLM et à la fenêtre contextuelle
Une solution naïve consisterait à augmenter le nombre de documents retournés par la recherche vectorielle.
Cependant cela pose un autre problème.
Les LLM (Large Language Models) disposent d’une fenêtre contextuelle limitée. Cela signifie qu’ils ne peuvent traiter qu’une quantité limitée de texte à la fois.
Si trop de documents sont fournis au modèle :
- la qualité de la réponse peut diminuer
- le modèle peut perdre de l’information importante
- les coûts de génération peuvent augmenter
L’objectif devient donc le suivant :
récupérer suffisamment de documents pour ne rien manquer, tout en ne conservant que les plus pertinents dans le contexte envoyé au LLM.
C’est précisément le rôle du reranking.
Pourquoi utiliser un reranker
Le reranking consiste à réévaluer les documents récupérés par la recherche vectorielle afin de réorganiser leur classement.
Plutôt que de se baser uniquement sur la similarité vectorielle, un modèle spécialisé analyse la requête et chaque document ensemble pour estimer leur pertinence réelle.
Cela permet :
- d’identifier les documents réellement utiles
- de filtrer les résultats moins pertinents
- d’optimiser les informations envoyées au LLM
Dans de nombreux cas, cette étape permet d’obtenir :
+20 à +40 % d’amélioration de pertinence dans les systèmes RAG.
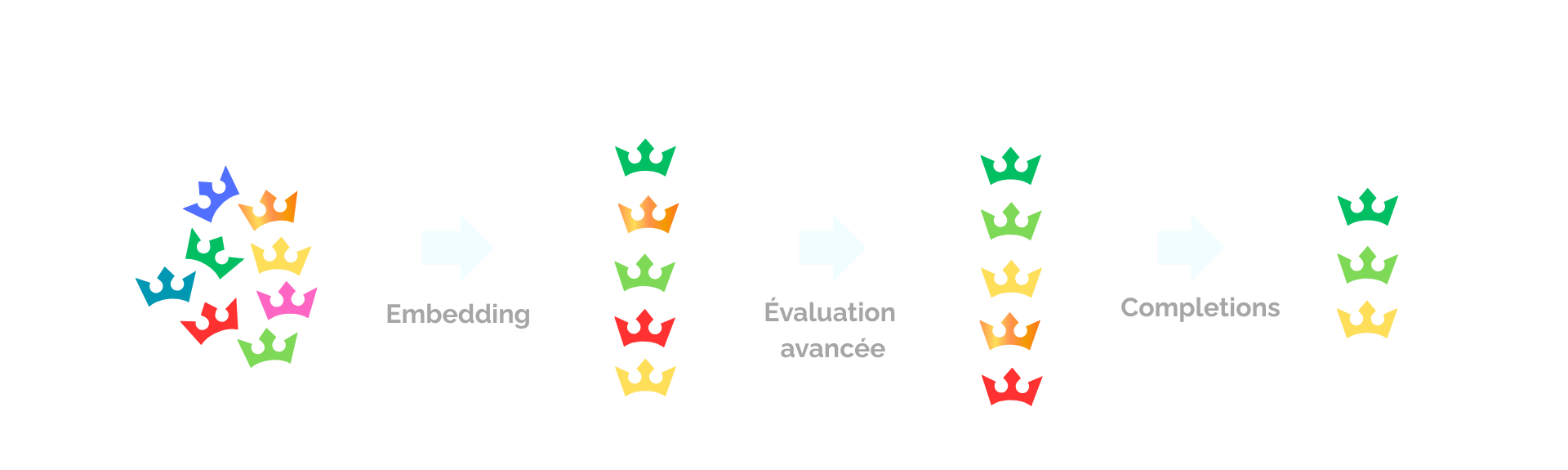
Le pipeline peut être résumé en trois grandes étapes :
1️ Search
La recherche vectorielle récupère un ensemble de documents potentiellement pertinents.
2️ Re-rank
Le modèle de reranking analyse chaque document en tenant compte de la requête afin de produire un classement plus précis.
3️ Answer
Seuls les documents les mieux classés sont envoyés au modèle de langage pour générer la réponse.
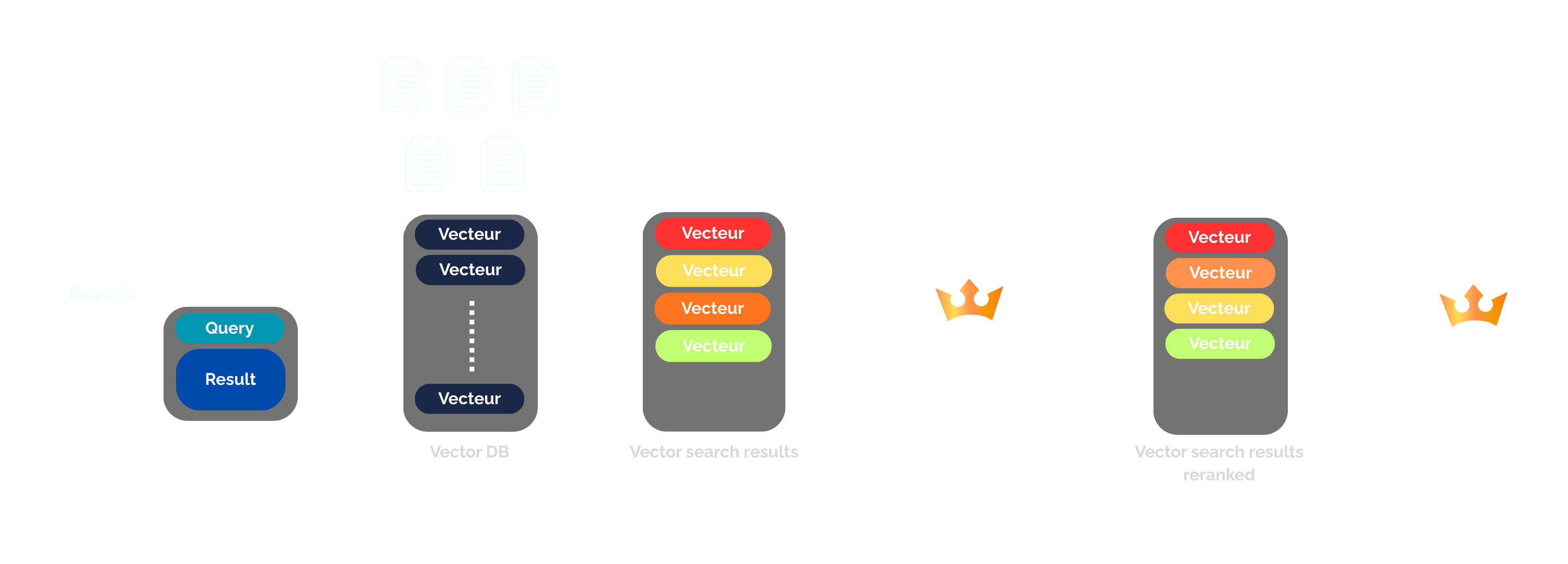
Fonctionnement global dans un pipeline RAG
Dans un pipeline RAG classique, le reranking intervient après la phase de retrieval.
Le processus se déroule généralement en plusieurs étapes :
- Transformation de la requête en embedding
- Recherche vectorielle dans la base documentaire
- Récupération des top K documents les plus proches
- Réévaluation de ces documents avec un modèle de reranking
- Sélection des documents les plus pertinents
- Envoi de ces documents dans le contexte du LLM
Modèle utilisé
Dans Clovis, nous utilisons le modèle : bge-reranker-v2-m3
Il s'agit d'un cross-encoder, ce qui signifie que la requête et le document sont analysés simultanément par le modèle pour produire un score de pertinence.
| Feature | Description |
|---|---|
| Type | Cross Encoder |
| Input | Query + Document |
| Output | Score de pertinence |
| Langues | Multilingue |
| Usage | Search / RAG |
Contrairement à un modèle d’embedding, le reranker ne produit pas de vecteurs.
Il produit directement un score de pertinence entre la requête et chaque document.
Exemple
Query
Comment fonctionne l'isolation thermique d'une maison ?
Résultat reranking
| Document | Score reranker |
|---|---|
| Isolation thermique extérieure | 0.97 |
| Isolation des combles | 0.91 |
| Isolation phonique | 0.12 |
Le reranker permet de replacer les documents pertinents en premier.
Cas d’usage
Le reranking est particulièrement utile pour :
- pipelines RAG
- moteurs de recherche documentaires
- assistants IA internes
- systèmes de question/réponse sur base documentaire